과학기술정책 이슈에 대한 심층분석 정보

이슈분석
이슈분석
[이슈분석 215호] 지능형 반도체 산업동향 및 시사점
- 국가 주요국
- 주제분류 핵심R&D분야
- 발간일 2022-06-03
- 권호 215
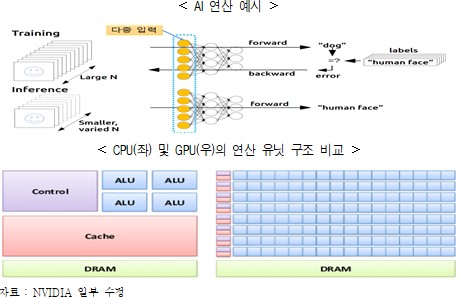
□ 인공지능 알고리즘 연산(학습, 추론)을 보조하는 전용의 반도체
ㅇ 지능형 반도체는 병렬 프로세싱 구조의 반도체 아키텍처를 활용하여 높은 성능, 낮은 전력 소모로 AI 연산을 실행(또는 지향)하는 연산 가속기
※ 학습데이터를 통해 도출된 학습 모델은 추론 연산에 적용, 추론의 정확도는 도출된 학습 모델에 좌우되고 이에 대응하는 학습 모델 개발을 위한 학습용 지능형 반도체의 주요 성능 스펙이 연산처리 속도(FLOPS)와 소비 전력이라면, 추론용 지능형 반도체는 정확도와 연산 레이턴시(latency)가 주요 성능 스펙
- AI 연산은 크게 학습과 추론으로 구분, 학습과 추론은 행렬에 의한 다중 병렬 연산 등에 기반
- CPU에서의 멀티 코어의 도입은 비약적으로 증대하는 단위 칩 면적당 전력 밀도*(W/cm2)를 낮추는데 기여하였으나 적은 수의 연산 유닛으로 대용량 변수의 병렬처리를 요하는 AI연산 대응에는 한계
* 인텔 CPU 경우, 멀티 코어없이 단일코어에 주력했다면 P6(1995)의 전력 밀도는 10W/cm2(핫플레이트에 해당) →1,000W/cm2 (로셋 분사 노즐에 해당) 증가되었을 것으로 추정(Micromachines 2021, 12, 665), 다중 연산 유닛의 도입은 필연
- CPU가 하이 클럭의 고성능 연산 유닛으로 순차 연산*인 반면, 지능형 반도체는 CPU 연산 유닛에 비해 성능은 다소 열위이나 수천개 이상의 연산 유닛으로 병렬연산을 처리
* CPU에서도 병렬연산이 가능하나 GPU와 비교해서 연산 유닛의 수가 현저히 적음
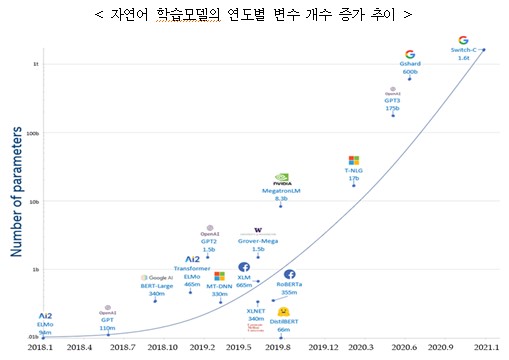
ㅇ 인공지능 알고리즘은 병렬 연산을 기반으로, 학습 모델 데이터 변수의 수가 증가일로에 있고, 추론용 반도체의 중요도도 증가 할 전망
- GPT 자연어 학습 모델 변수의 경우 2018년 1억1천개 → 2020년 1천7백억개, 구글의 자연어 학습 모델(Switch-C)은 1조6천개로 지수함수적으로 증가하여 PIM 구조 등이 부상
- AI 알고리즘의 발전, 이에 따른 학습 모델의 완성도가 올라갈수록 추론용 반도체 비중은 증가
- 복합지능 등 다양한 학습 모델에 대응하는 초거대 AI 연산의 학습 모델 개발과 저지연 및 고정확도를 지원하는 지능형 반도체는 필수
- AI 연산을 위한 반도체는 CPU, GPU, FPGA, ASIC 등이 있으나, 연산 적용의 유연성은 CPU, 가성비와 효율성은 ASIC이 가장 유리
※ CPU를 기준으로 GPU 및 ASIC의 학습 데이터 처리 능력은 1,000배, 추론의 속도는 ASIC이 100배, 정확도는 CPU > GPU > FPGA > ASIC 순 [What They Are and Why They Matter (CSET, 2020.4)]
□ 본고에서는 지능형 반도체 최신 산업 동향 고찰을 통해 관련 시사점 및 정책 제언을 도출
1. 지능형 반도체 주요 기업 및 산업 동향
□ 시장은 GPU 중심, 응용 분야별로는 CPU, GPU, 온칩 메모리 등의 집적, 다양한 폼팩터(칩렛 등)의 시도로 AI 연산 능력 극대화
ㅇ (NVIDIA) AI 관련 반도체 시장 리더로 자율주행차, 데이터센터, HPC 등 다양한 AI 반도체 솔루션으로 시장을 선점
- A100 대비 최대 30배 성능(SM, Transformer Engine, NVlink, MIG, HBM3 등)의 데이터 센터용 (학습 및 추론용) 반도체 GPU H100 (TSMC 4nm, 120TFLPS(FP16)/700W) 발표(`22.3)
① SM(Streaming Multiprocessor) : 텐서코어(FP8, 16, 64, BF16, TF32, INT8 지원), Int 32, FP 32, 64 코어, 외부 메모리(HBM 등)와 Cuda 메모리간 데이터 전송을 가속하는 TMA(Tensor Memory Accelerator), 동적할당 AI 알고리즘* 특화 연산 기능인 DPX(Dynamic Programming Instruction) 등이 탑재
* Smith-Waterman algorithm(동적 할당법으로 문자열 정렬), Floyd-Warshall algorithm(최단경로 검색) 등
② Transformer Engine : 자연어 학습 알고리즘(단어와 언어 어순 정보의 인코딩 및 디코딩 등 수행) 연산 가속기
③ 4세대 NVlink : GPU to GPU 인터페이스로 900GB 대역폭 제공(PCIe Gen5의 7배)
④ 2세대 MIG(Multi Instance GPU) : 1개의 GPU로 7개의 GPU Instance의 독립 연산을 지원
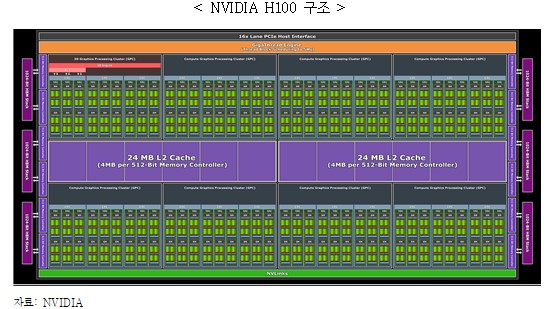
- 소비전력과 대면적 칩이 단점이나 데이터 센터, HPC 등 시장 요구사항에 필요한 AI 연산 기능 등을 탑재하고 이에 강력한 API CUDA의 구축, GPU 운영체제 DriveOS 등 제공으로 시장 지배력을 유지
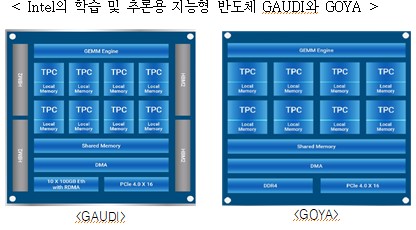
ㅇ (Intel) Habana Labs 인수, 학습 및 추론용 인공지능 반도체 확보, 독자적인 칩 공정 기술을 적용한 GPU 및 AI 가속기를 내재한 데이터 센터 CPU 등 개발
- 학습용 반도체 Gaudi에는 대용량 고속 데이터의 칩 내 전송을 위해 HBM2/SRAM 메모리를 활용하고 Nvidia의 V100 대비 3.5배의 이미지 처리(소비전력 최대 300W)
① 딥러닝 모델 전용을 위한 Amazon AI칩 EC2 DL1 Instances(`21.10)에 적용
② 스토리지 전문기업 DDN과 협력, Gaudi 기반의 학습용 토탈 솔루션 출시(’21.11)
- 추론용 반도체 Goya의 경우, ResNet50(이미지 분류용 벤치마크 테스트) 기준 7ms/15,488fps의 레이턴시 구현
※ 학습용 지능형 반도체 GAUDI의 경우 대용량 데이터 처리를 위해 HBM을 집적
- 시장의 GPU 수요 대응을 위해 128개의 코어(Xe core), HBM2e/캐쉬 메모리 등 이종 다이(Heterogeneous Die)를 집적, EMIB*, Foveros** 공정을 적용한 폰테 베키오(Ponte Vecchio) GPU(45TFLOPS(FP32기준))를 개발
※ ResNet 추론 성능 테스트 결과 43,000image/s(소비전력 600W 추정)
* EMIB : 다이와 다이 간 연결을 위한 인터포저(Interposer)를 대체하는 인텔고유의 이종(Heterogeneous) 다이(Die)간 임베디드 형태의 국소공간 배선 기술. 인터포저 대비 TSV 및 추가 금속 배선 층 없는 공정으로 칩렛(Chiplet) 구현을 위한 인터커넥트 기술
** Foveros : EMIB가 다이 간 확장의 2차원 연결인 반면 3D 적층 연결을 위한 액티브(Active) 인터포저를 적용한 패키징 기술
- DDR5. HBM, 옵테인 메모리, 학습 및 추론을 위한 AI 가속기* 등을 탑재한 데이터 센터용 CPU Saphire Rapids
개발(`21.8)
※ 데이터센터 시장에서 시장 점유율 하락에 대한 대응
* NVIDIA의 행렬연산 코어 텐서코어와 동일한 AMX(Advanced Matrix Extension), 데이터 전송을 가속화하는 DSA(Data Streaming Accelerator)를 내장
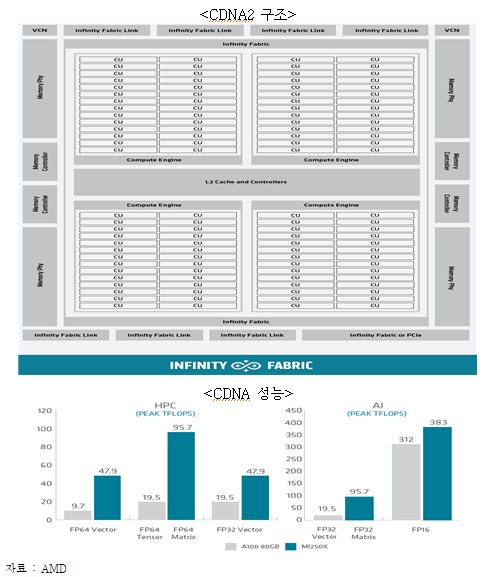
ㅇ (AMD) 고유의 GPU 구조 CDNA2를 탑재한 듀얼 칩렛(Chiplet) 기반의 AI 가속기 INSTINCT MI250 출시 (’21.11)
- 내부 메모리 구조 HBM2e를 채택, 3.2TB/s 구현 및 최대 383 TFLOPS/500~600W의 성능
- CPU-AI 가속기 또는 GPU-GPU 간 Infinity fabric Link로 데이터 전송 최대 800GB/s 구현
- NVIDIA CUDA와 동일한 GPU 플랫폼 ROCm을 구축하여 다양한 AI 연산을 지원
ㅇ (Tesla) 데이터센터용으로 25개의 D1칩*을 패키징한 Dojo(데이터 센터용)와 자동차에서 AI 연산을 처리하는 FSD 칩(Full Self Driving, 자율주행차용)을 개발
- 데이터 센터용 D1은 362TFLOPS(BF16), 칩간 대역폭 9 TB/s를 구현 25개를 집적한 Dojo는 9 PFLOPS(16kW)의 성능 발표
※ D1은 슈퍼컴퓨터에 활용되는 칩 중 가장 많은 캐쉬 메모리*(424MB)와 RISC-V 일부를 내재, RISC-V의 용도는 칩내 데이터 네트워크 제어용
* 최근 AMD의 데이터 센터용 CPU Milan-X는 804 MB의 캐쉬메모리 발표(`21.11)

- -- 
- ARM의 Cortex(A72)기반으로 12개의 CPU, GPU(600 GFLOPS), 2개의 NPU, SRAM을 집적한 라이다 없이 영상으로만 자율주행이 가능한 FSD칩(36.8TOPS(int8), 삼성 14nm FinFet) 개발(`19)
※ 자율주행 차량용 보드는 FSD 2개의 칩, 소비전력 100W로 144TOPS(int8) 구현, 1개의 FSD칩 소비전력은 36W
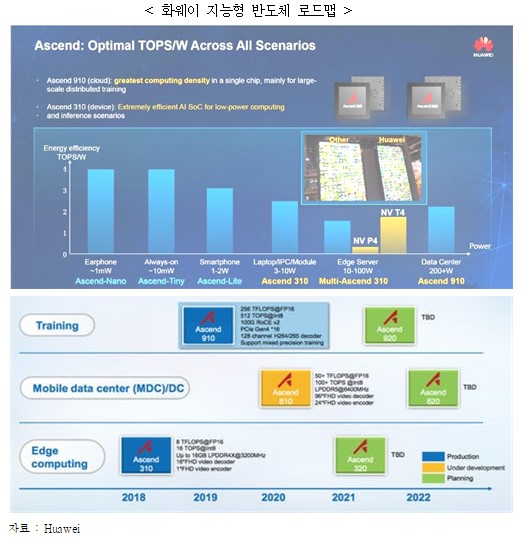
ㅇ (화웨이) 데이터 센터 및 엣지 컴퓨팅 등을 위한 지능형 반도체 로드맵을 발표하였으나 미국의 반도체 제재로 칩 제작 중단 상태
- 자사의 클라우드 사업 확장을 위해 학습용 AI 반도체 Ascend910은 320TFlops/310W, 엣지 컴퓨터용 Ascend310 11TFlops/8W의 발표(`19), 이후 미국의 반도체 제재로 답보 상태
- 미국의 반도체 제재에 대응, 독자적인 반도체 사업 진출을 위해 중국 정부의 지원으로 중신난팡(中芯南方)*과 협력을 추진
* 중신난팡(中芯南方) : SMIC(중신궈지), 중신홀딩스, 국가반도체펀드, 상하이반도체펀드의 공동출자로 설립된 회사
※ 출처 : 디일렉(`22.1)
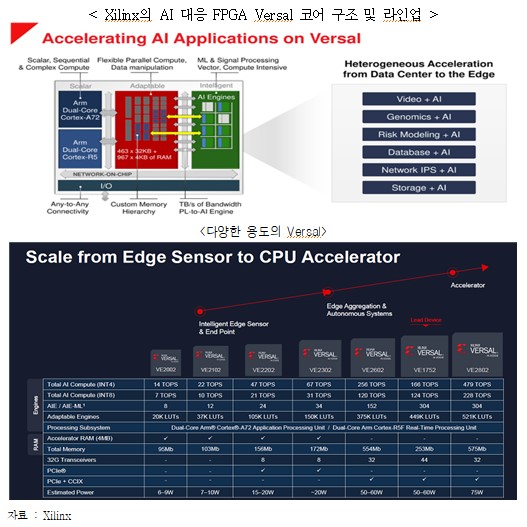
ㅇ (Xilinx) FPGA 분야 주도 기업으로 Edge에서 클라우드까지 적용 가능한 FGPA 제품군 Versal을 출시 중이고, AMD에 인수(490억 달러, `22.2)
- ARM의 Cortex A(고성능 application용) 및 R(real time 및 safety용)의 듀얼코어 CPU와 별도의 AI 엔진(행렬연산(2차원 텐서)이 아닌 벡터 연산 유닛(1차원 텐서) 구조, AI 연산 외 DSP 등 다양한 혼합 연산에 대응), FPGA를 집적
※ Edge용은 10W 미만의 소비전력으로 14TOPS, CPU 연산을 보조하는 AI 가속기는 479Tops/75W의 성능. NVIDIA의 Jetson AGX Xavier*와 비교 최대 4.7배의 성능 확인
* Jestson AGX Xavier : NVIDIA의 저전력 AI 추론 칩 모듈로 32TOPS/30W, 30TOPS/40W 두 개의 모델
- FPGA는 다양한 AI연산 대응이 가능하지만 대용량 학습 모델 개발보다 ASIC으로 전환 전 초기 모델개발이나 추론용으로 시장 점유 전망
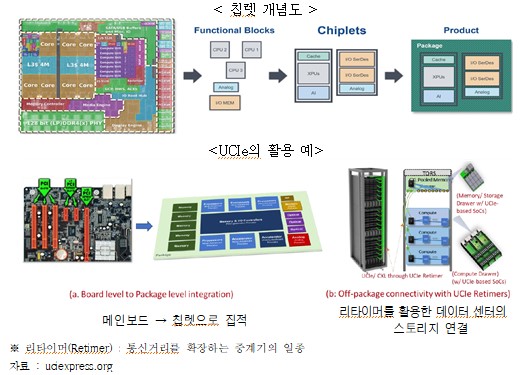
□ 칩렛(Chiplet) 구성의 새로운 인터커넥션 표준 UCIe의 등장
ㅇ AMD, INTEL, 삼성, TSMC, MS, Meta 등 칩렛 인터페이스 UCIe* 컨소시엄 구성
* UCIe : Universal Chiplet Interconnect Express
- 고성능 다기능 칩, 수율간의 트레이드오프, 확장성에 대한 요구 등으로 다기능 One Die → 단 기능 Multi Die 패키징으로 진화
- 이에 따른 패키징 내 칩 간 고속 데이터 인터페이스, 칩 영역 외 엣지와 데이터 센터에서 활용 가능한 개방형 인터페이스 표준 UCIe 추진(`22.3)

□ AI 연산의 저전력 및 메모리 병목에 대한 해결 → 뉴로모픽 반도체와 PIM
ㅇ 뉴로모픽 반도체는 인간 뇌의 동작을 모방하여 초저전력으로 구동 가능한 인공지능 반도체
- 폰 노이만 구조는 연산을 담당하는 연산 유닛(CPU, APU, GPU 등)과 학습데이터를 저장하는 메모리가 물리적으로 분리되어 있는 구조
- 이러한 방식은 AI 연산과 같은 대규모 데이터와 연산이 복잡할수록 오랜 시간이 소요되며, 연산유닛과 메모리 사이의 병목 현상(bottleneck)으로 인해 데이터 처리에 한계
- 인간의 뇌는 1,000억 개의 뉴런과 100조 개 이상의 시냅스가 병렬 연결되어 있고, 뇌 신경 전달 신호는 event 기반의 스파이크 신호로 구성되어 단 20W 수준의 저전력으로 기억/연산/추론/학습 등 고도의 연산을 동시에 수행
- 메모리 병목의 해결과 저전력 구현을 위해 스파이킹 신호, 시냅스 및 뉴런 등 인간의 뇌 신호처리를 모사한 스파이킹 뉴럴 네트워크(SNN)기반 지능형 반도체 연구가 활발하나 뇌의 기전과 SNN 이론은 정립되지 않은 상태
- 뉴로모픽 컴퓨팅에 대해 학계에서는 ① Fine-grained Parallelism(병렬연산), ② Event-driven computation(이벤트 기반의 연산과 정보처리), ③Adaptive, self-modifying(자기 학습) 등 3가지 기능을 정의
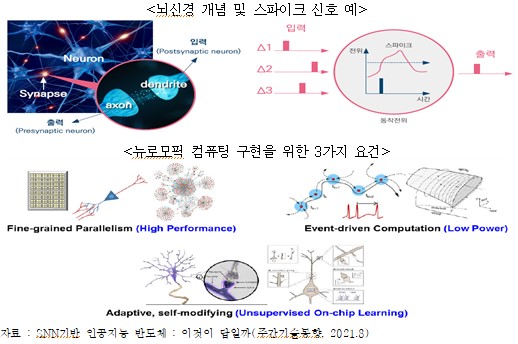
- 이를 위해 뇌신경을 크게 3차원 연결 신경망, 신호처리를 담당하는 뉴런, 메모리와 신호 전달함수 기능 등을 수행하는 시냅스(Synapse)로 모델링하고, 이의 반도체 구현을 위해 라우팅, Memoristor, NVM(RRAM, PRAM, MRAM 등) 등을 이식한 구조 연구가 활발
- 뉴로모픽 반도체는 PIM과 연산코어를 합성한 구조로 볼 수 있으며, PIM에서의 메모리가 단순 메모리 기능이라면 뉴로모픽 반도체의 메모리는 전달함수 기능의 포함으로 신경모사를 지향
ㅇ 지능형 반도체의 발전추이는 GPU → ASIC → 뉴로모픽(neuromorphic) 기반으로 발전될 전망
- AI 연산 초기에는 GPU 기반의 하드웨어가 시장을 견인하였으나, 향후 지능형 반도체의 중심은 뉴로모픽이 차지할 전망. 그러나 SNN 및 뇌의 기전 연구 등 기반 연구의 선행이 필요
- GPU는 소비전력의 약점으로 데이터 센터에서 학습모델 개발용, CPU는 추론용, FPGA는 엣지에서 경량 추론 및 학습용, 뉴로모픽 반도체는 저전력, 빠른 데이터 처리 성능으로 학습과 추론, 데이터 센터 및 엣지 컴퓨터 전 부분에서 활용 기대
ㅇ반도체 설계 강자(Intel, IBM 등), 스타트업 등을 중심으로 미래 시장 선점을 위해 기술개발 경쟁이 심화
- (Intel) ‘로이히(Loihi)’ 발표(`17) 이후, 차세대 모델 ‘로이히(Loihi)2*’와 스파이크 신경망을 지원하는 SW 프레임워크 LAVA** 출시(`21.9)
* 기존 모델대비 약 8배 많은 뉴런 수(1백만개)와 10배의 처리 속도, Intel 4 공정(7nm로 추정)
** 텐서플로우(TensorFlow)와 파이토치(Pytorch)는 스파이크 신경망은 미지원
※ 인텔의 뉴로모픽 반도체 설계 우선순위는 기능>성능>소비전력으로 칩 내 뉴로모픽 코어 외 별도의 CPU를 집적하여 칩 내의 데이터 인코딩 및 디코딩 통신과 graded spike event 등을 지원하는 것이 특징
- (IBM) 미국 국방부의 SyNAPSE 프로젝트에 참여하여 2014년에 최초의 뉴로모픽 칩인 TrueNorth를 개발, 25~275mW 수준의 전력으로 초당 1,200~2,600 프레임 이미지를 분류
※ 64×64 시냅틱 코어를 구성하고 코어당 라우터를 집적하여 시냅틱 코어 간 연결망을 형성하고 코어내 SRAM으로 신경망의 가중치, 임계값, 출력값 등을 저장
- (Innatera Nanosystems*) 시냅틱 유닛간 원거리, 근거리 망 중첩 연결로 다중 팬아웃 구현으로 AI 연산의 유연성을 제공하고 시냅틱 유닛당 200fJ**로 저전력 뉴로모픽 반도체(TSMC 28nm)를 구현(`21.7)
* 델프트 공대 스타트업
** Femto Joule
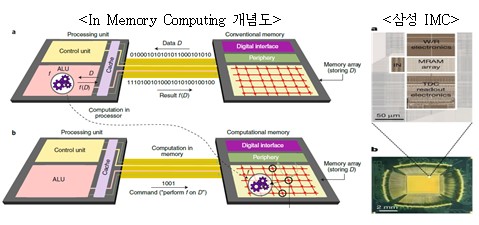
ㅇ 뉴로모픽 반도체가 스파이킹 신경망(SNN) 연산을 위한 반도체인 반면, PIM 반도체는 범용 신경망을 지원하고 메모리에 연산유닛을 접목하여 메모리 병목을 해소
- 삼성은 세계 최초로 MRAM 기반의 인 메모리 컴퓨팅(IMC, In-Memory-Computing) 반도체를 개발(`21.12)
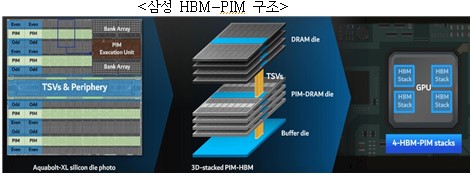
- 또한 HBM-PIM(코드네임: AQUABOLT-XL) 구조, 메모리 제품군으로 확장하여 AXDIMM, LPDDR5-PIM을 개발
① (AXDIMM*) DRAM 모듈 버퍼칩에 AI엔진을 장착한 제품을 SAP의 HANA** 서버에 테스트, 성능은 2배 증가, 에너지 소비는 40% 감소
* AXDIMM : Acceleration Dual in-line Memory Module
** HANA : SAP의 클라우드 시스템
② (LPDDR-PIM) On-chip AI 실현이 가능한 모바일 메모리 제품군으로 적용하고 음성인식, 번역, 챗봇 등으로 다양한 AI엔진 모델을 실험하였으며, 성능은 2배 에너지 소비는 60% 절감
※ Xilinx Alveo AI 가속기에 HBM-PIM을 집적하여 시스템 성능 2.5배, 에너지 소비 60% 감소
2. 지능형 반도체 스타트업 현황
□ 지능형 반도체 시장 선점을 위한 글로벌 스타트업 기업 진출 활발
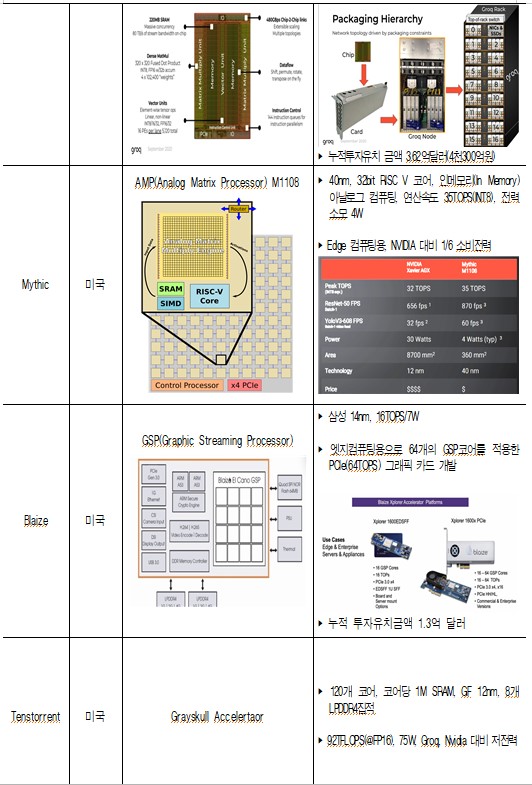
ㅇ (국외) 창의적이고 도전적인 설계(웨이퍼 스케일, 재구성, 광 연산기 등)로 기술 개발 중


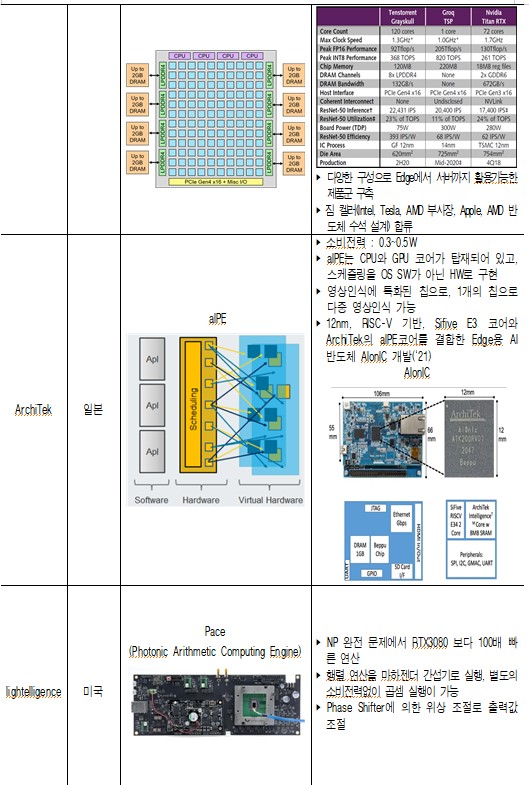

ㅇ (국내) 서버, Edge, IoT 등 틈새시장에서 글로벌 경쟁력을 확보하기 위한 노력 진행 중
- (딥엑스) 엣지 디바이스, 자율주행차, 데이터센터 등 각 어플리케이션에 특화된 반도체인 ‘제네시스(GENESIS)’를 개발하였으며, `22년 하반기에 출시 예정
※ (제네시스 주요 성능) 연산속도: 10TOPS, 전력소모: 1W
- (리벨리온) 인텔 Goya보다 30% 성능이 우월한 금융 특화 반도체 개발(`21.12)
- (모빌린트) 자율주행차, 사물인터넷(IoT) 기기, 블랙박스, 폐쇄회로(CC)TV, 도어록 등 저전력 AI 반도체 개발에 주력
- (디퍼아이) 영상인식에 특화된 AI 반도체 개발하고 `22년 상용화 추진(`21.10)
- (Furiosa AI) AI 반도체 벤치마크 MLPerf에서 엔비디아의 T4 보다 우수한 성능의 칩 워보이(Warboy) 개발
※ 2022년 상반기 삼성전자 파운드리(반도체 위탁생산)에 위탁해 양산 시작할 계획 발표
3. 시사점
ㅇ 데이터 센터 연산 칩은 인텔 중심의 x86 → x86 + (ARM, GPU, AI 가속기)로 전환
- 전 산업의 AI 확산과 학습 모델 개발로 인해 데이터 센터의 부담은 가중될 전망
- 데이터 센터의 AI 연산 요구 증대는 지능형 반도체 수요를 촉발하고, 대용량 고속 메모리, 인터페이스 등 관련 하드웨어의 수요와 기술의 혁신은 더욱 가속될 전망
- 인공지능 연산 → 지능형 반도체 수요 → 파운드리 시장 촉진 → 저전력 /고밀도 집적을 위한 미세 공정의 수요 증대 → 관련 반도체 장비시장도 꾸준한 성장 전망
※ 반도체 칩의 활용까지 설계 → 공정 → 패키징 → 검사 → PCB 단계로 진행, 각 단계별 반도체 재료, 공정 및 검사장비 등으로 산업 에코 시스템이 형성
ㅇ 시장 경쟁력은 낮은 소비전력(학습), 낮은 레이턴시(추론) 구현과 다양한 AI 알고리즘 대응이 관건
- 스토리지 및 메모리 데이터 병목과 이를 해결하기 위한 반도체 구조와 인터페이스, 소비전력 등에 의한 성능의 최적화와 다양한 AI 연산에 대응하는 호환성이 경쟁력의 핵심
- 뉴로모픽 반도체의 경우, 뇌 기전, SNN의 AI 알고리즘, SW플랫폼 등 관련 이론 및 기술 정립이 필요하고 시스템 반도체의 파괴적 혁신 기술인 바 조기에 대규모 정부 지원 필요
- 광 기반의 AI 가속기에 대한 해외 벤처 및 관련 연구가 활발하고, 조기에 원천기술확보를 위해 기초 연구지원도 절실
ㅇ 지능형 반도체 시장은 아직 초기 단계로, 스타트업에게 무한한 가능성을 선사하는 동시에 스타트업 간 생존 경쟁은 불가피
- 국내 반도체 산업 인프라와 정부의 적극적인 지원은 글로벌 기업으로 성장 가능한 토종 팹리스 기업 태동의 자양분
- 지능형 반도체 시장 선점을 위한 국가 차원의 체계적이고 전략적인 기술개발 로드맵을 마련하고, 신기술 R&D 투자 및 반도체 기업 생태계 간의 가치사슬 인프라 구축 등을 위한 관련 사업 예산 증액과 범부처 합동의 신사업 개발 및 지원 필요
※ 작성자: 정보통신기획평가원(IITP) 권요안 수석(schnabel@iitp.kr)





