국내외 과학기술정책에 대한 주요 정보

주요동향
주요동향
글로벌 IT기업, 인공지능(AI) 기반 번역기술 개발 경쟁 주목 원문보기 1
- 국가 한국
- 생성기관 AI 타임스
- 주제분류 핵심R&D분야
- 원문발표일 2020-10-30
- 등록일 2020-11-20
- 권호 179
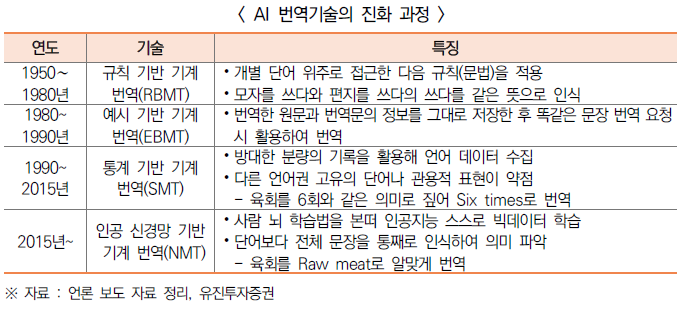
□AI・자연어 처리 기술 진일보…인간 수준의 번역 서비스 발전을 견인
○ 사람처럼 문맥을 읽는 ‘인공 신경망 기술’의 발전으로 오역이 줄고 표현력이 늘어나면서 사람과 대화가 가능한 수준으로 텍스트를 작성하는 AI 번역기술 진일보
- 최근 AI 번역기술은 AI가 문장의 맥락을 스스로 학습하여 뜻을 옮겨주는 만큼 종전의 기계 번역보다 훨씬 자연스러운 결과 도출
- 이는 컴퓨터 프로그래밍처럼 인공적으로 만들어진 언어가 아닌 사람과 사람 사이 실제 사용하는 언어를 순서・처리하는 자연어 처리(Natural Language Processing) 기술 발전 때문
○ 글로벌 IT기업들은 사용자가 원하는 쉽고 편리한 맞춤형 AI 번역기술을 활용한 서비스를 제공하기 위해 연구개발에 박차
□구글・MS・페이스북 등 글로벌 IT기업, 다국어 번역 모델 공개
○ (구글) 101개의 언어를 번역할 수 있는 다국어 AI 모델 mT5를 깃허브에 오픈 소스로 공개(10.23)
- 101개 언어 데이터 세트에 대해 사전 학습된 Google T5 모델의 다국어 변형인 mT5*는 3억 ~ 130억 개의 매개 변수(예측에 사용되는 모델 내 변수)를 포함하며 100개 이상의 언어를 학습할 수 있는 모델
* mT5는 mT5-Small(3억 개의 매개 변수), mT5-Base(6억 개의 매개 변수), mT5-Large(10억 개의 매개 변수), mT5-XL(40억 개의 매개 변수), mT5-XXL(130억 개의 매개 변수) 등 5가지 모델로 출시
- 중복되는 문장과 데이터를 제거하고 비속어를 걸러내어 편향(Bias)을 줄여낸 것이 특징
- 다국어 모델을 대상으로 의미론적 사고・구문론적 사고 성능과 언어 간 일반화(cross-lingual generalization) 능력을 측정하는 Xtreme 벤치마크에서 mT5 모델이 타 모델보다 높은 점수를 기록
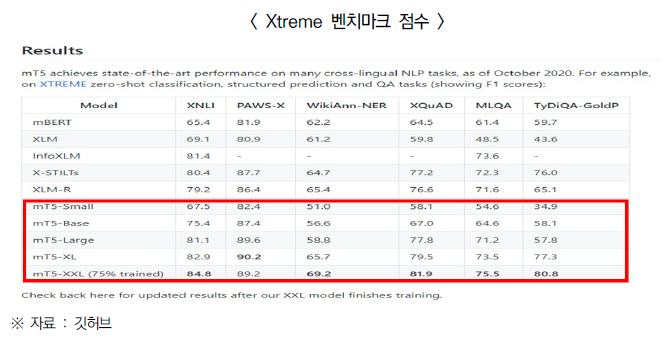
- 한편, 구글은 mT5를 개발하기 위해 인터넷 웹사이트에서 크롤링된 750GB 분량의 영어 텍스트 데이터 C4(사전 훈련 데이터 셋)와 107개의 각종 언어 데이터가 포함된 자료를 기반으로 학습을 진행
○ (MS) 94개 언어를 번역할 수 있는 AI 번역 모델 ‘T-ULRv2’ 발표(10.19)
- T-ULRv2는 총 5억 5,000만 개의 매개변수(예측에 사용되는 모델 내 변수)를 포함
- 다국어 마스크 언어 모델링(multilingual masked language modeling, MMLM), 번역 언어 모델링(translation language modeling, TLM), 교차 언어 대비(cross-lingual contrast, XLCo)를 학습하며 다른 언어로 된 문장에서 마스크 된 단어를 예측하여 번역하는 훈련을 거쳐 T-ULRv2를 개발
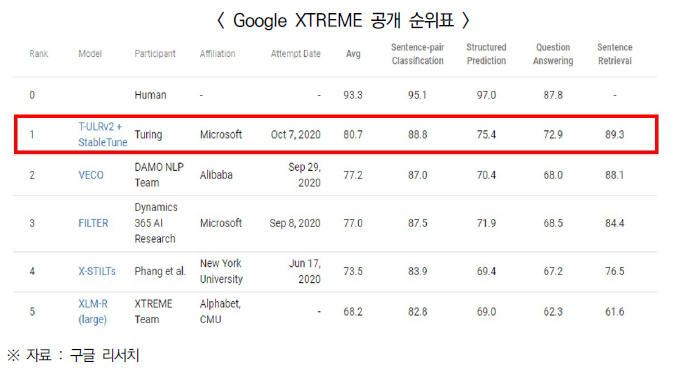
- 한편, T-ULRv2는 Google XTREME 공개 순위표에서 평균 80.7점을 획득하여 1위를 달성
○ (페이스북) 100개 언어를 번역하는 AI 언어 번역 모델 M2M-100을 깃허브를 통해 공개(10.19)
- 뉴스피드에서 매일 발생하는 200억 건의 번역을 AI 모델에 학습 시키고 100개 언어로 구성된 75억 개의 데이터셋을 구축하는 과정을 거쳐 M2M-100을 개발
- 유사성이 높은 언어 간에 번역 품질을 높이기 위해 분류 및 지리, 문화적 유사성에 따라 14개 계열로 그룹화 작업을 진행했으며 싱할라어와 자바어 간 번역 등 통계적으로 번역 수요가 거의 없는 데이터쌍은 작업을 최소화
- 기존 번역 모델은 한국어, 중국어, 프랑스어 등 영어가 아닌 언어 간에 번역을 할 때도 중개언어인 영어로 한 번 번역을 거쳐야 했지만 M2M-100은 중개 언어로 영어를 사용하지 않고 각 언어를 직접 비교하여 번역하는 것이 특징
- 특히 기계번역 평가 방법 중 하나인 BLEU 미터법에서 영어 중심의 AI번역기보다 10점 이상 높은 점수를 획득하며 원어민에 가까운 해석이 가능
- 이 외에도 M2M-100은 유사한 언어 간에 정보를 공유하므로 충분한 학습을 거치면 AI 모델이 이전에 학습하지 않은 언어도 번역
□국내 IT기업, AI 번역 모델 앞세워 국제대회서 수상하는 등 기술 경쟁 가세
○ (삼성SDS) 최근 글로벌 AI 독해 경진대회 ‘핫팟QA(HotpotQA)’와 한국어 독해 경진대회 ‘코쿼드 1.0(KorQuAD 1.0)’ 및 ‘코쿼드 2.0(KorQuAD 2.0)’에서 모두 1위 차지
- 핫팟QA는 미국 카네기멜론, 스탠퍼드대, 캐나다 몬트리올대가 만든 데이터셋 기반의 글로벌 AI 독해 경진대회로 위키피디아 전체에서 답을 찾는 방식으로 가장 난이도가 높은 핫팟 QA 풀위키세팅(HotpotQA Fullwiki Setting) 부문에서 1위 기록
※ 핫팟QA 테스트에서는 질문에 대해 2개 이상 문장을 근거로 정답을 제시해야 하므로 수준 높은 논리적 추론 능력이 필요
- 코쿼드는 AI 자연어 이해 학습용 한국어 표준데이터로 해당 데이터를 이용한 AI 독해 능력을 평가
- 코쿼드 1.0 테스트에서는 AI가 한정된 내용을 읽으면 질문에 대한 정확한 답을 제출해야하며 코쿼드 2.0 테스트에서는 한국어 위키피디아 전체에서 답을 찾는 방식으로 장문의 답변을 요구
- 특히 삼성 SDS는 코쿼드 2.0에서 참가팀들 중 유일하게 사람의 능력을 능가하는 점수를 기록
○ (삼성전자) 연구개발(R&D) 조직인 삼성리서치 산하 폴란드연구소와 베이징연구소는 IWSLT(구술 언어 번역 국제워크숍)*에서 1위를 차지
* IWSLT는 자연어 처리 분야 최고 수준의 국제학술대회인 전산언어학협회(ACL) 콘퍼런스에 포함돼 권위를 인정받은 워크숍
- 삼성전자 폴란드연구소는 이번 워크숍에서 영어로 된 테드 강연을 독일어로 번역하는 과제를 수행해 ‘오디오-텍스트 번역’ 부문 1위를 수상
- 입력된 음성을 곧바로 번역하는 엔드 투 엔드(E2E) 시스템을 사용해 여러 단계를 거칠 때 발생할 수 있는 오류 감소
- 베이징 연구소는 일본어와 중국어 간 번역 능력을 평가하는 ‘오픈 도메인 번역’ 부문에서 우승
- ‘상대적 위치 어텐션’으로 사전 데이터 처리의 정교함을 높여 번역의 정확도를 끌어올렸으며 바이트 페어 인코팅(Byte Pair Encoding)을 통해 단어를 의미 있는 단위로 쪼갠 결과물과 문장을 구성한 조각들을 비교하는 등 성능을 향상
○ (파파고) AI 번역 평가 모델 ‘팟퀘스트(PATQUEST, Papago Translation Quality Estimation)’가 국제 기계번역 대회 ‘WMT20※’의 문서 품질 평가에서 1위, 문장 단위 직접평가(영・독 번역)에서 4위를 차지
※ WMT(세계 기계번역 워크숍)는 IWSLT(구술 언어 번역 국제워크숍), WAT(아시아 번역 품질 평가대회) 등과 함께 기계 번역 분야에서 세계적인 권위를 인정받고 있는 학회
- 문서 단위 품질로 품질을 평가하는 것에 대한 난이도가 매우 높은 것으로 알려진 대회에서 수상했다는 것에 의미
- 파파고는 인공 신경망 기반 번역으로 구 단위가 아닌 문장 단위로 번역하며 인공 지능이 전체 문맥을 파악한 뒤 문장 안에서 단어와 순서, 문맥과 의미 차이를 번역
- 파파고가 대회에 출품한 팟퀘스트는 번역 품질을 평가하고 번역 모델의 성능을 높이는 평가 모델로 AI데이터를 생성하고 이를 모델학습에 적용하는 과정을 자동화하여 번역 품질 평가 정확도를 향상한 것이 특징





