국내외 과학기술정책에 대한 주요 정보

주요동향
주요동향
글로벌 IT업계 新격전지,‘초거대 인공지능’기술개발 촉발 원문보기 1
- 국가 한국
- 생성기관 한국일보
- 주제분류 핵심R&D분야
- 원문발표일 2021-05-26
- 등록일 2021-06-28
- 권호 193
□ 알파고 뛰어넘는 ‘초거대(Hyperscale) 인공지능(AI)’ 발전 주목
◌ 초거대 인공지능은 대용량 데이터를 빠르게 처리할 수 있는 슈퍼컴퓨팅 인프라를 기반으로 딥러닝(심층학습) 효율을 크게 높인 차세대 인공지능을 의미
- 데이터 분석·학습·판단은 물론 기사 작성, 창작, 코딩 등 광범위한 작업을 인간의 뇌처럼 완성도 높게 수행. 즉 종합적·자율적으로 사고·학습·판단·행동하는 인간의 뇌 구조에 버금
가는 인공지능
- 2016년 구글 딥마인드가 딥러닝 기술로 개발한 ‘알파고’가 바둑에만 특화됐다면, 초거대 인공지능은 활용 범위가 넓어 기업의 비즈니스 모델과 서비스를 다양화·고도화하는데
응용 가능
◌ 초거대 인공지능을 개발하기 위해 슈퍼컴퓨터를 활용해 ‘파라미터(parameter: 매개변수)’ 성능을 크게 높이는 것이 필수
- 파라미터는 인간 뇌의 학습·연산 기능을 담당하는 ‘시냅스’와 비슷한 역할로 파라미터 수가 많아질수록 인공지능 성능을 높이는 셈
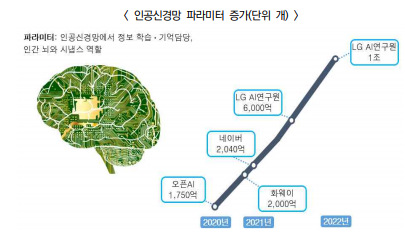
- 인간 뇌 속의 시냅스 수는 100조 개에 달하는 반면 2019년까지 구글·페이스북 등이 보유한 인공지능은 파라미터가 수억 개, MS가 170억 개 수준
◌ 사람처럼 다방면에서 지적 활동을 수행하기 위해 인공지능이 학습할 수 있는 데이터양과 속도에 한계가 있었지만 2020년 6월 GPT-3 등장으로 비약적인 발전을 입증
- 일론 머스크 등이 주축으로 설립한 오픈AI 연구소가 개발한 GPT-3는 4,990억 개 중 가중치 기반으로 샘플링된 3,000억 개의 데이터셋과 1,750억 개의 파라미터로 학습
※ 오픈AI가 2018년 첫 출시한 GPT-1은 1억 1,700만 개 매개변수로 학습하였고 2019년 공개한 GPT-2는 모델의 크기에 따라 약 1억 2,400만 개에서 15억 개로 GPT-1의 10배 수준이
며 GPT-3는 매개변수 1,750억 개로 GPT-2의 100배 규모
- 아직 학습 결과를 설명하는데 다소 미흡하고 일부 편향된 결과를 보이기도 하지만 지속적인 연구를 통해 극복, 보완해 나갈 것으로 예상
◌ 최근 네이버·KT·SK텔레콤·LG·구글·화웨이 등 국내외 업계는 초거대 인공지능 잠재력에 주목하며 그 간의 기술성과, 전략적 협업과 개발 계획 등을 잇달아 공개
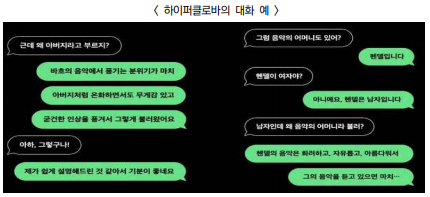
□ 네이버, GPT-3 뛰어넘는 한국어 모델 ‘하이퍼클로바’ 발표
◌ 온라인 개최(5.25)한 ‘네이버 AI 나우(NAVER AI NOW)’ 컨퍼런스에서 세계 최대 한국어 인공지능 언어모델인 ‘하이퍼클로바(HyperCLOVA)’ 공개
- 하이퍼클로바(HyperCLOVA)는 오픈AI(OpenAI)의 GPT-3(1,750억개 파라미터)를 뛰어넘는 2,040억 개 파라미터 규모로 개발
- 자연어(영어·한국어 등 일상에서 쓰는 언어) 데이터 학습량은 GPT-3의 6,500배 이상 학습해 세계에서 가장 큰 한국어 초거대 인공지능 언어모델
- GPT-3가 영어 중심으로 학습해 국내 기업이 도입하기에 한계가 있었는데 하이퍼클로바는 학습 데이터의 97%가 한국어로 이루어져 있어 차세대 AI 주도권 확보에 나섰다는
점에 의의
- 대규모 파라미터를 통해 학습한 결과, 맥락을 이해하는 자연스러운 대화를 이어가며 종합·자율적 사고 가능
- 국내 최대 인터넷 플랫폼을 운영하며 쌓아온 대규모 데이터 처리능력도 하이퍼클로바의 핵심 자원
※ 네이버는 하이퍼클로바 개발을 위해 5,600억 개 토큰(token, 말뭉치)의 한국어 대용량 데이터 구축
- 앞서 하이퍼클로버 개발을 위해 2020년 10월 대규모 투자를 통해 700페타플롭스(PF) 성능의 슈퍼컴퓨터 도입(1페타플롭스는 1초에 1,000조 번 데이터 연산을 수행할 수 있는
컴퓨터 성능)
◌ 향후 쇼핑·지도 등 10개 이상의 네이버 서비스에 하이퍼클로바를 적용 예정이며 궁극적으로 인공지능을 ‘모두의 능력’으로 만드는 도구로 쓰이도록 한다는 포부
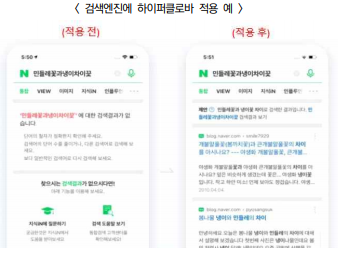
- 이미 5월 초 검색엔진에 도입해 사용자가 검색어를 잘못 입력해도 올바른 단어로 바꿔주거나 적절한 검색어를 추천하는 기능 수행
- 네이버 쇼핑에 입점한 판매자를 대신해 상품 마케팅 문구를 자동으로 작성, 창작자를 대신해 스토리만 입력하면 웹툰 그리기, 학생 대신해 공부해야 할 내용을 빠르게 요약하
거나 모르는 내용을 알려주는 작업 등도 가능해질 것이라고 설명
- 또한 중소상공인(SME)·크리에이터·스타트업 등을 지원하는 기술도 구상 중이며 작문·요약·데이터 생성 등 다양한 역할을 수행할 수 있어 활용처가 폭넓을 것으로 전망
◌ 서울대·카이스트와 각각 수백억 원 규모의 초거대 인공지능 공동연구소 설립에 나서는 등 관련 투자를 확대하며 기술개발 속도
- ‘서울대-네이버 초대규모 인공지능 연구센터(SNU-NAVER Hyperscale AI Center)’를 설립해 초대규모 한국어 언어모델을 발전시킨다는 목표
- 나아가 언어·이미지·음성을 동시에 이해하는 초대규모 인공지능을 함께 개발해 글로벌 기술을 선도한다는 구상
- 또한 카이스트와 ‘초창의적 AI 연구센터(KAIST-NAVER Hypercreative AI Center)’를 설립하고 초대규모 인공지능을 활용한 기술을 공동 개발 예정
□ SK텔레콤·KT·LG 등 국내 주요 기업도 출사표
◌ (SK텔레콤) 업종과 장벽을 아우르는 초협력을 기반으로 공동 개발 추진
- 2020년 6월 GPT-2에 상응하는 첫 한국어 학습 오픈소스 모델 ‘KoGPT-2’ 개발 성공에 이어 금년 5월 성능을 개선한 KoGPT-2 모델 2.0 버전 공개
- 올 4월에는 국립국어원과 국어에 적합한 차세대 인공지능 모델 개발에 협력하며 고객 응대를 비롯해 문학·역사·시사 등 다양한 분야에 적용 가능한 범용언어모델(GLM) 개발에
나설 계획
- 또한 카카오와 인프라·데이터·언어모델 등 전방위 협력을 맺고 1,500억 개 파라미터를 갖춘 자연어처리 인공지능 모델 개발을 목표로 집중 투자 예정
◌ (KT) 2017년 출시했던 음성인식 인공지능 기가지니를 GPT-3를 뛰어넘는 초거대 인공지능으로 발전시킬 계획
- 지난 5.23일 초거대 인공지능 개발을 명시적 목표로 삼고 네이버처럼 카이스트와 공동 인공지능 연구소를 설립하기로 결정
- 올 하반기 연구소를 출범시켜 초거대 인공지능용 컴퓨터 인프라를 구축·지원하고 이르면 2022년 연구 성과를 내겠다는 전략
◌ (LG그룹) 올 하반기까지 6,000억 개 파라미터, 2022년 상반기까지 1조 개 이상 파라미터를 갖춘 초거대 인공지능을 만들겠다는 계획
- 소재 발굴, 소프트웨어 코딩, 논문 분석과 학술 데이터베이스 구축, 디자인 시안 제작 등에 초거대 인공지능을 활용할 계획
- 초거대 인공지능 개발을 위해 1초에 9경 5,700조 번의 연산 처리가 가능한 컴퓨팅 인프라 구축 등에 향후 3년 간 1억 달러 투자
□ 해외에서는 구글·화웨이 광폭 행보
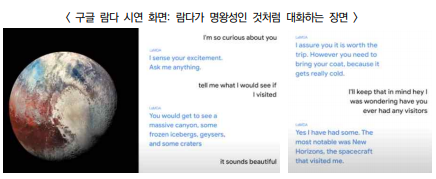
◌ (구글) 개발자회의(5.18)에서 공개한 대화형 인공지능 언어모델 ‘람다(LaMDA)’는 사람의 대화 방식을 이해하고 정답이 없는 질문에도 자연스런 대화 가능
※ 람다는 대화 애플리케이션을 위한 언어모델(Language Model for Dialogue Applications)을 의미하며 트랜스포머(Transformer) 오픈 소스 신경망 아키텍처에 구축
- 구글 CEO 피차이는 “람다는 미리 정의된 답변을 학습하지 않아 자연스러운 대화를 할 수 있으며 어떤 대화도 수행할 수 있다”고 강조
- 반면 아직 개발 진행 중으로 모든 것을 제대로 하지는 못할 뿐 아니라 때로는 말도 안 되는 반응을 보일 수도 있다고 솔직하게 인정
- 구글은 새로운 상호작용을 탐구하기 위해 내부적으로 람다를 사용하고 있으며, 조만간 제3자 테스트를 위해 개방할 계획
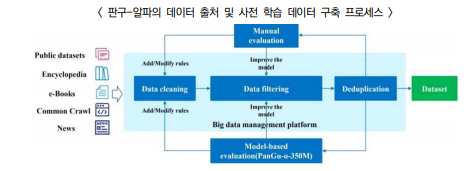
◌ (화웨이) 대규모 자연어 처리(NLP) 모델 ‘판구-알파(PanGu-α)’ 개발 관련 논문을 아카이브(arXiv)에 게재(5.26)
- 판구-알파는 1.1테라바이트(TB) 분량의 중국어 전자책, 백과사전, 뉴스, 소셜미디어 게시글, 웹페이지에서 추출한 언어를 학습
- 연구진은 2,000억 개의 파라미터를 보유하고 있어 까다로운 중국어를 텍스트로 요약하고 질문·답변에 뛰어나 다양한 대화 생성에 우수한 성능을 갖추었다고 강조
- 5차원 병렬 기능을 결합해 모델에 적용했으며 CAN4가 구동하는 2,048개의 어센드 인공지능 프로세서 클러스터로 훈련
- 현재 판구-알파의 코드·데이터세트를 오픈소스로 공개한 가운데 향후 비영리 연구기관이나 타 기업들이 판구-알파에 접근을 확대할 수 있도록 다각적인 방법을 모색한다는
구상