국내외 과학기술정책에 대한 주요 정보

주요동향
주요동향
韓 기업, 글로벌 수준의 기술력 입증…AI 연구 중심으로 도약 원문보기 1
- 국가 한국
- 생성기관 카카오엔터프라이즈
- 주제분류 핵심R&D분야
- 원문발표일 2022-06-23
- 등록일 2022-07-15
- 권호 218
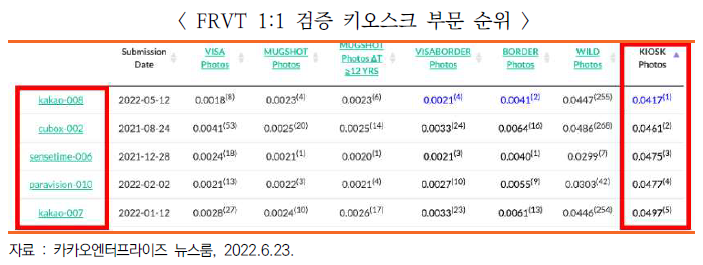
□ (카카오엔터프라이즈) 美 국립표준기술연구소 AI 얼굴인식 테스트에서 우수한 성과
ㅇ 세계 기술 표준을 선도하는 미국 국립표준기술연구소(NIST: National Institute of Standards and Technology) 주관의 ‘얼굴인식 벤더 테스트(FRVT: Facial Recognition Vender Test)’ 1:1 검증(verification) ‘키오스크(kiosk)’ 부문에서 카카오엔터프라이즈가 1위 차지
- 얼굴인식 분야의 글로벌 Top-tier 대회인 FRVT는 얼굴 정보 대조를 통한 출입국심사, 여권 불법 복제 탐지 등 민간·사법·국가 보안 영역에서 활용되는 자동 얼굴 인식 알고리즘의 성능을 측정하는 대회
- 특히 키오스크 부문은 얼굴이 아래쪽을 향해 왜곡과 소실이 잘 발생하는 이미지를 다루기 때문에 다른 부문에 비해 난이도가 높은 분야
- FRVT 1:1 검증에서 사용된 카카오엔터프라이즈 기술은 실제 카카오엔터프라이즈 본사의 얼굴 인식 기반 출입 시스템인 ‘워크스루(walk-through)’에 적용
- 카카오엔터프라이즈는 이번 결과를 바탕으로 얼굴인식 모델을 더욱 고도화하여 기존 대비 정확도를 높이고 이를 기반으로 스마트시티·지능형 CCTV·지능형 관제 등 서비스에 순차적으로 제공 예정
- 2위를 한 ‘출입국 심사(border)’ 부문에서는 선두 기업과 불과 0.0001 차이를 보였고, ‘비자 출입국 심사(VISA border)’ 부문 4위, ‘상반신(mugshot)’ 부문 4위에 오르는 등 4개 부문에서 Top5에 랭크
- 고도의 AI 얼굴인식 기술력을 필요로 하는 원천기술 부문에서 국내 기업이 괄목할만한 성과와 경쟁력을 확보한 데 의의

□ (네이버) ‘CVPR* 2022’에서 두 자리 수 논문 발표하며 글로벌 리더십 강화
* CVPR(Computer Vision and Pattern Recognition)은 국제전기전자공학회(IEEE)와 국제컴퓨터비전재단(CVF)이 1983년부터 공동 주최하는 대표적인 AI 국제 학술대회. 금년에는 미국 뉴올리언스에서 온·오프라인을 병행하며 6일 간 진행(6.19∼24)
ㅇ 네이버클로바가 ‘CVPR 2022’에서 구두 논문 1편을 포함해 정규 논문 14편, 워크샵 논문 3편을 발표하며 글로벌 AI 기술 리더십 입증
※ 국내 기업의 연구조직이 CVPR에서 두 자릿수 논문을 발표한 것은 네이버클로바가 최초이며 구두 발표 기회는 학회 제출 논문 중 4% 이내에 해당하는 최상위 평가를 받은 연구에만 부여
- 컴퓨터 비전의 다양한 기반 기술뿐 아니라 연구 성과를 실제 네이버 서비스에 적용하는 과정에서 기여할 수 있는 연구에 중점
- 서울대와 협업으로 네이버 초대규모 AI센터 연구 결과를 담은 총 3건의 논문을 포함해 산학협력 성과도 소개

ㅇ 이 외에도 네이버클로바는 AAAI, CHI, ICASSP, ICLR, ICML, Interspeech 등 상반기에만 글로벌 AI 학회에서 60편의 정규 논문을 등재하며, 압도적인 연구 역량을 바탕으로 국내 1위를 넘어 글로벌 AI 리더로 성장
※ AAAI(4건), CHI(2건), ICASSP(7건), ICLR(13건), ACL(2건), CVPR(14건), NAACL (5건), ICML(5건), Interspeech(8건)
ㅇ 한편 네이버웹툰은 독자 개발한 웹툰 관련 AI 기술(자동배경분리, 웹툰미) 연구 논문 2편 소개
- ‘자동배경분리’ 기술은 몇 번의 클릭만으로 원하는 이미지에서 배경을 분리하고 범위만 선택해서 뽑아낼 수 있는 기술
- 원본 이미지의 배경 제거에 걸리는 시간을 획기적으로 줄여 웹툰에 쓰인 이미지를 쉽고 빠르게 편집할 수 있으며 현재 개발 진행 중인 웹툰 전용 편집 도구의 핵심 기능이 될 예정
- ‘웹툰미’ 기술은 사람 얼굴이나 배경 등 실제 장면을 웹툰처럼 바꿔주는 기술. 창작자의 작업 시간을 단축시켜줄 수 있을 뿐만 아니라 ‘웹툰미’를 활용한 새로운 콘텐츠 제작 가능
□ (LG AI연구원) ‘CVPR 2022’에서 단독 연구 논문을 포함해 총 7편 논문 발표
ㅇ 언어와 시각 정보를 모두 다루는 초거대 멀티모달 AI 구현의 핵심 기술 ‘L-Verse’의 성과를 담은 단독 연구 논문(L-Verse: Bidirectional Generation Between Image and Text)이 구두 발표 대상으로 선정
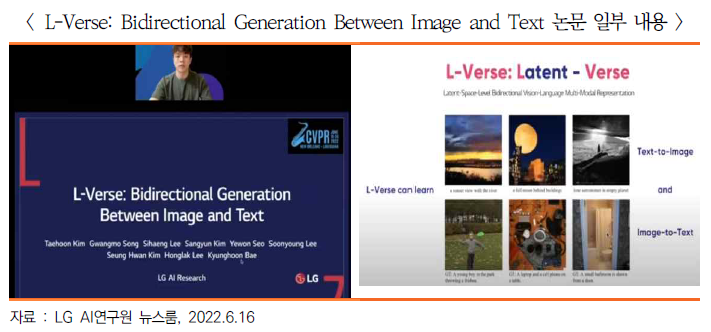
- 이번 논문을 토대로 개발한 세계 최초의 언어와 시각 정보 간 양방향 소통 가능한 초거대 멀티모달 AI ‘엑사원’ 핵심 기술도 소개
- 엑사원에 사진을 보여주면 사진 속 모습대로 ‘한 소년이 푸르른 공원에서 녹색 플라스틱 원반을 던지고 있다’는 문장이 자동 완성되고 ‘흐르는 강물과 일몰 풍경’이라는 텍스트를 보여주면 관련 이미지가 화면에 등장
- 학회 현장 부스에서는 Self-supervised representation learning, Continual learning, Active learning 등 비전 검사에 활용된 기술과 난제를 극복한 사례, 복잡한 문서를 인간의 개입 없이 AI가 읽고 이해하는 DDU(Deep Document Understanding) 시연, AI와 인간 협업의 미래를 제시한 AI 아티스트 틸다(Tilda) 등 그 동안 성과 소개
ㅇ LG AI연구원은 현재 기술력을 증명하는 것에서 나아가 연구 생태계를 세계로 확장하며 ‘글로벌 AI 연구 허브’로 도약한다는 목표
- 향후 AI 원천기술 연구개발에 속도를 내는 동시에 연구 인력을 2배 이상(출범 이후 1년 만에) 늘리며 자체 연구 역량을 강화
- 최근에는 서울대학교 AI대학원과 초거대 멀티모달 AI 공동 연구 및 인재 육성을 위해 ‘SNU-LG AI 리서치 센터’를 설립(4.26)
- 해외에서는 지난 3월 AI 선행 기술 연구와 북미 AI 인재 확보를 위해 美 미시간주에 ‘LG AI 리서치 센터(LG AI Research Center, Ann Arbor)’를 신설하여 미시간대학교와 연구 협력을 진행하고 캐나다 토론토대학교와도 AI 난제 해결을 위한 원천기술 공동 연구 진행
- 향후 북미의 여러 AI 명문 대학 및 연구 기관과의 산학 협력을 강화하며 오픈 이노베이션을 확대할 계획
□ (삼성 리서치 AI센터) ‘CVPR 2022’에서 논문 20편 채택
ㅇ 각 글로벌 AI센터(서울·뉴욕·케임브리지·토론토·몬트리올·모스크바 등)에서 연구한 논문을 제출하며 성과 소개
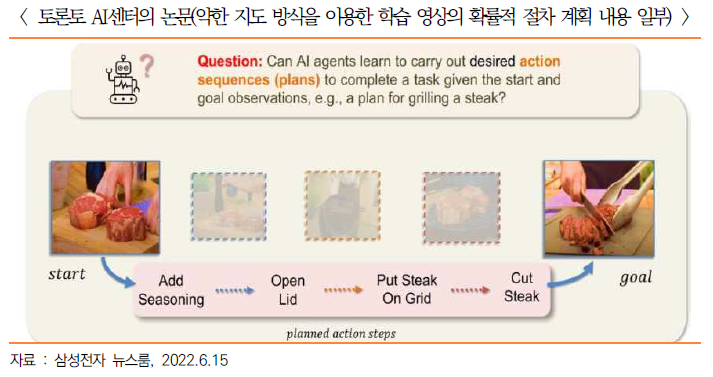
- 토론토 AI센터에서 제출한 구두 발표 논문 중 첫 번째는 ‘약한 지도 방식을 이용한 학습 영상의 확률적 절차 계획(P3IV: Probabilistic Procedure Planning from Instructional Videos with Weak Supervision)’으로, 차세대 AI 시스템 구축에 필요한 연구
- ‘절차 계획’은 인간 행동을 분석하고 모방하는 AI 연구에 있어 매우 중요하며 특히 요리·제품 설치· 수리 같은 문제 해결에서 주목
- 예를 들면 ‘요리’ 같은 학습 영상에서 각 단계의 구간 시간을 일일이 입력하는 수고와 시간을 줄였으며 인터넷 등에서 발췌된 자연어와 이미지의 조합을 AI가 학습하여 중간 절차를 자동 예측하고 확률 모델로 불확실성도 보완하는 방식을 제시
- 두 번째는 ‘야간 신경 ISP 훈련을 위한 야간 영상 합성(Day-to-Night Image Synthesis for Training Nighttime Neural ISPs)’ 연구
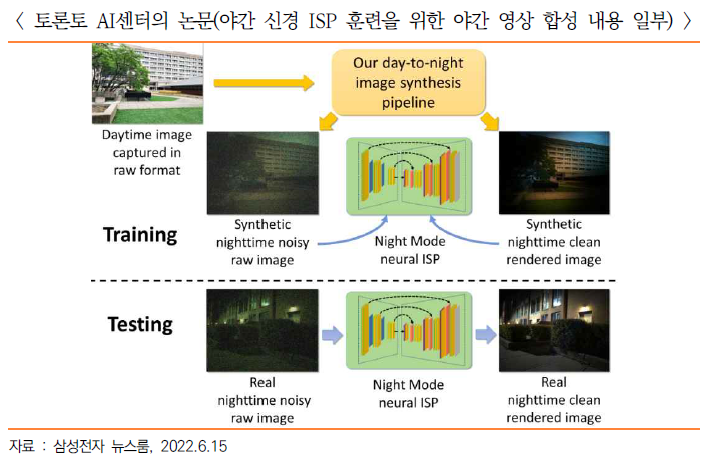
- 이는 스마트폰 카메라 나이트 모드의 신경 이미지 시그널 프로세서(ISP)에 필요한 야간 이미지 학습 데이터를 획득하는 방법에 관한 것으로, 깨끗한 이미지를 쉽게 얻을 수 있는 낮 시간에 촬영한 이미지를 야간 이미지로 변환하는 기술
- 모스크바 AI센터는 ‘싱글 뷰 깊이 추정(Single-View Depth Estimation, SVDE)’에 대한 연구, ‘다층 이미지를 사용한 스테레오 확대(Stereo Magnification with Multi-Layer Images)’ 연구 논문 공개
- 케임브리지 AI센터는 ‘변이 오토인코더 추론 성능을 개선하는 가우시안 프로세스 모델링 기법’ 논문과 대량 데이터 기반으로 잘 학습된 AI 모델 적용을 통해 ‘퓨샷 러닝의 성능을 개선할 수 있는 단순 파이프라인 한계의 극복’ 논문 발표





