국내외 과학기술정책에 대한 주요 정보

주요동향
주요동향
데이터 量보다 質에 중점을 두는 ‘소형언어모델(sLLM)’ 경쟁 원문보기 1
- 국가 미국
- 생성기관 매일경제
- 주제분류 핵심R&D분야
- 원문발표일 2023-07-23
- 등록일 2023-10-13
- 권호 248
□ 슈퍼 컴퓨팅 만큼의 HW사양이 필요없는 소형언어모델(sLLM) 급부상
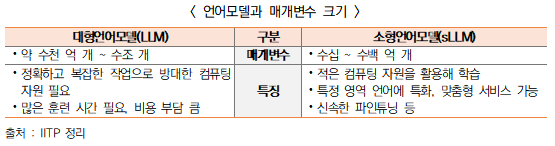
ㅇ 머신러닝 매개변수(parameter)를 줄여 비용을 아끼고 미세조정(fine-tuning)으로 정확도를 높이는 ‘맞춤형 LLM’ 의미
- 작은 용량에 따른 머신러닝 소요시간과 비용 절감*
* 기존 LLM은 학습에 수개월이 걸리고 비용은 수십만~수백만 달러 발생, 구글 PaLM은
슈퍼컴퓨터 두 대로 50일 이상 훈련, GPT-3는 훈련 비용이 1,000만 달러(약 132억 원) 소요
※ 오픈AI의 ‘GPT-3.0’와 ‘GPT-3.5(챗GPT)’는 1,750억 개, 구글의 ‘PaLM’은 5,400억 개에 달하지만, sLLM은 60억~70억 개에 불과
ㅇ (샘 알트먼, 오픈AI) 매개변수 추가를 통한 대규모 언어모델(LLM) 크기 증가만으로 AI 성능을 향상시키는 데는 한계
- 어느 정도까지는 매개변수가 많아질수록 모델의 학습능력이 향상되고 답변 정확도가 제고되지만, 항상 비례하지는 않는다고 설명
- AI 모델 크기가 AI 성능과 비례하는 것은 아니며, AI 성능은 매개변수 크기 외에도 다른 다양한 요소들에 의해 좌우될 수 있음
□ 소형언어모델(sLLM) 개발에 나선 국내외 기업과 대학
ㅇ (마이크로소프트) GPT-3.5의 매개변수 1% 미만에 해당하는 13억 개 매개변수로 구성된 소규모 언어모델 ‘파이-1(phi-1)’을 공개해 주목
- 파이-1은 휴먼이벌(HumanEval) 테스트에서 GPT-3.5보다 우수한 성능을 보인 것으로 알려져, 모델 크기를 확대하는 것이 아닌 품질 개선을 통해 성능을 달성할 수 있다는 것을 입증
ㅇ (메타) 매개변수를 키우기보다 LLM 훈련에 사용하는 토큰(텍스트 데이터 단위)의 양을 늘려 품질 향상
- 매개변수가 70억(7B)~650억(66B) 개의 다양한 크기의 버전을 공개
ㅇ (데이터브릭스) 돌리(Dolly) 2.0은 100달러 비용으로 1대 서버에서 3시간 훈련해 구축한 매개변수 60억 개의 소형언어모델
- 1.0 버전은 알파카의 데이터셋 활용, 2.0버전은 데이터브릭스 자체 구축한 데이터셋을 학습, 상업 목적으로 사용 가능
ㅇ (스탠포드 대학) ‘라마 7B’ 기반의 sLLM ‘알파카(Alpaca)’ 출시
- 알파카는 매개변수 70억 개로 클라우드 서비스(컴퓨터 8대)를 이용해 3시간 만에 훈련 완료, 비용도 600달러(약 79만 원)에 불과
ㅇ (LG AI 연구원) 엑사원 2.0 버전은 매개변수에 따라 총 6종(17억 개, 88억 개, 250억 개, 700억 개, 1,750억 개, 3,000억 개)으로 다양
- 매개변수를 줄인 대신 질 좋은 데이터를 학습시키고 미세 조정(파인튜닝)하는 방식으로 성능 개선
ㅇ (카카오) 초거대 AI의 파라미터(매개변수) 경쟁보다는 비용 합리적인 ‘KoGPT 2.0’ 모델로 버티컬 서비스 계획(B2C 중심)
※ 60억-130억-250억-650억 개까지 다양한 크기 모델을 테스트, 비용 합리적인 AI 모델 생성





